deepseek appv1.2.1

- 软件分类:安卓软件/常用工具
- 软件语言:中文
- 更新时间:2026/3/22 15:22:51
- 支持系统:Android/IOS
- 开发商:暂无
- 来源:互联网
- 详情
- 下载地址
- 同类热门
- 推荐专题
DeepSeek App 是由 DeepSeek 官方打造的智能 AI 助手,搭载全球领先的 DeepSeek-V3 与全新 DeepSeek-R1 模型,为用户提供免费、高效、多场景的智能交互体验。支持中国大陆手机号、微信及 Apple ID(iOS)一键登录,App 与网页端数据实时同步,历史对话无缝衔接。无论你是在学习、办公还是探索知识,DeepSeek App 都能通过联网搜索、深度思考模式、文件上传识别(含图片文字提取)等功能,随时随地为你提供精准、高效的智能支持。
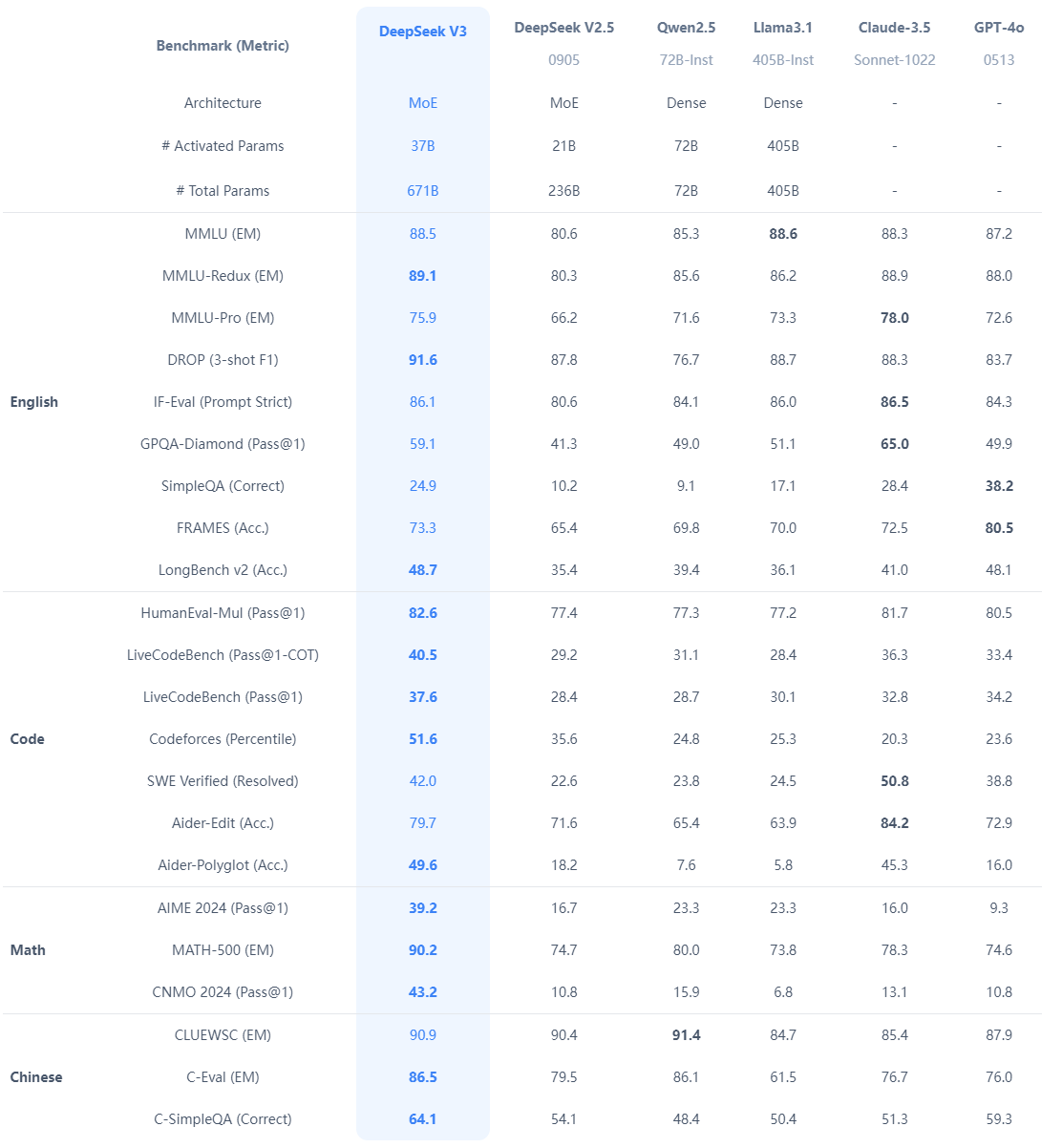
世界领先的模型性能:DeepSeek-V3
DeepSeek-V3 在推理速度上实现显著跃升,大幅优化响应效率与资源消耗。在当前主流大模型评测榜单中,DeepSeek-V3 稳居开源模型榜首,综合能力已可与全球顶尖闭源模型比肩,为用户带来接近行业天花板的智能体验。
重磅升级:DeepSeek-R1 正式发布
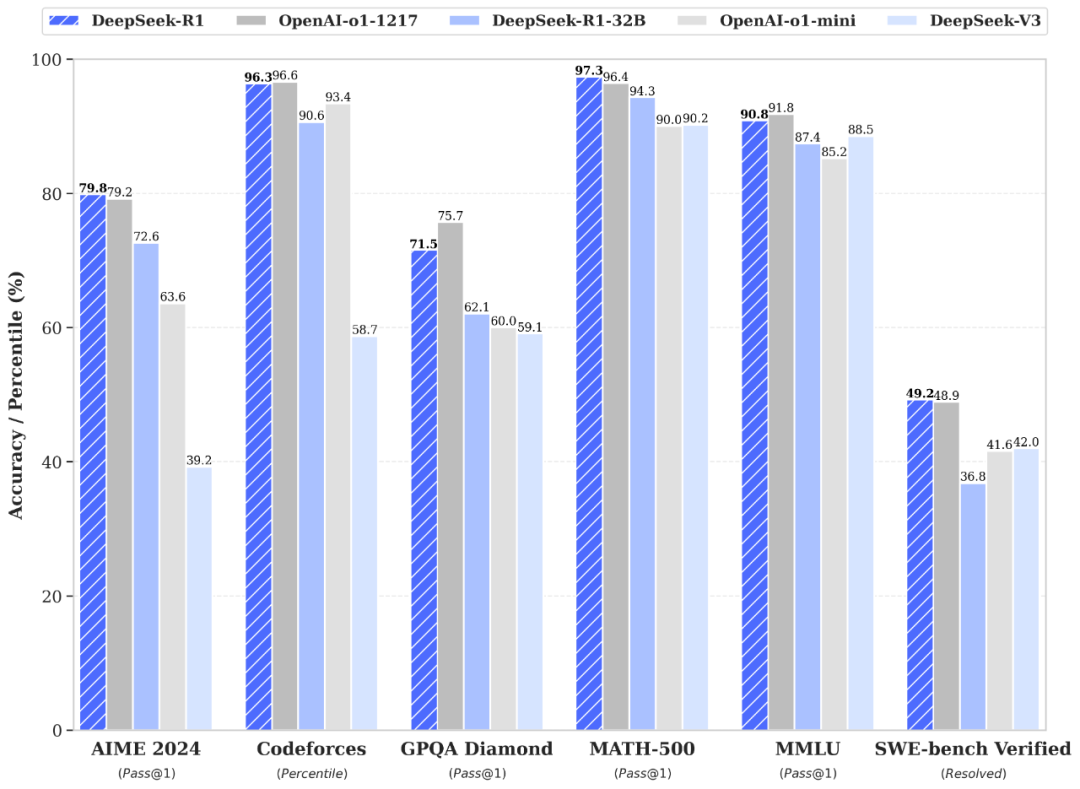
DeepSeek 全新推出 DeepSeek-R1,性能全面对标 OpenAI o1 正式版,并同步开源模型权重,推动技术普惠与社区共创。R1 不仅上线官方 API,还开放“思维链”输出功能——只需设置 model='deepseek-reasoner' 即可调用,适用于高阶推理任务。
DeepSeek-R1 在后训练阶段大规模采用强化学习(RL),在极少人工标注数据的前提下,显著提升数学、代码与自然语言推理能力。其表现已在多项权威基准测试中与 OpenAI o1 正式版持平。
为促进技术透明与协作,DeepSeek 已将 R1 的完整训练方法公开,相关论文详见:
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
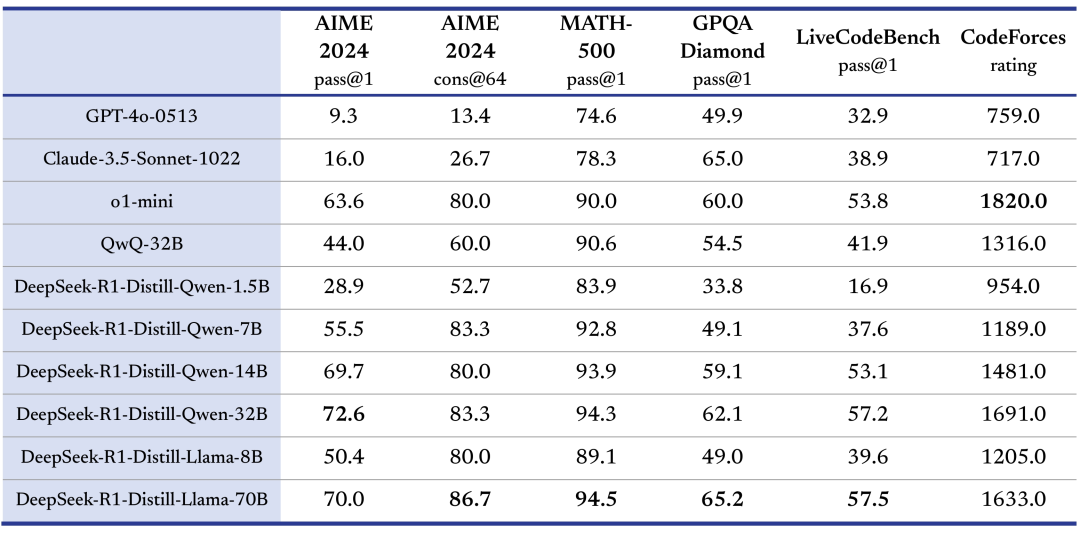
小模型也有大智慧:蒸馏版超越 o1-mini
在开源 660B 参数的 DeepSeek-R1-Zero 与 DeepSeek-R1 的同时,DeepSeek 利用 R1 的高质量输出,成功蒸馏出 6 个轻量级开源模型。其中,32B 与 70B 版本在多项任务上表现媲美 OpenAI o1-mini,为资源受限场景提供强大替代方案。
所有模型已在 HuggingFace 开源,欢迎开发者体验与集成:
https://huggingface.co/deepseek-ai
真正开放:MIT 许可 + 支持模型蒸馏
为降低使用门槛、激发社区创新,DeepSeek 对开源协议进行全面优化:所有模型权重统一采用标准 MIT License,完全开源、允许商用、无需申请授权。此举取代了此前的 DeepSeek License,以更通用、更友好的方式服务全球开发者。
此外,DeepSeek 明确更新用户协议,**正式允许用户基于模型输出进行“模型蒸馏”**,即利用 DeepSeek 模型生成的数据训练自己的新模型。这一举措极大拓展了技术复用与二次开发的可能性,助力 AI 生态繁荣。
随时随地,开启深度思考
无论是通过 DeepSeek 官网还是官方 App,用户均可一键启用“深度思考”模式,直接调用最新 DeepSeek-R1 模型,完成复杂推理、逻辑分析、代码生成等高阶任务。移动端与桌面端体验一致,数据实时同步,让智能触手可及。
开发者友好:兼容 OpenAI API,快速接入
DeepSeek API 采用与 OpenAI 兼容的接口格式,开发者可直接使用 OpenAI SDK 或兼容工具,仅需修改 base_url 为 https://api.deepseek.com/v1 即可无缝切换。注意:此处 v1 为 API 版本标识,与模型版本无关。
当前 deepseek-chat 模型已全面升级至 DeepSeek-V3,接口保持不变,调用时指定 model='deepseek-chat' 即可享受最新性能。
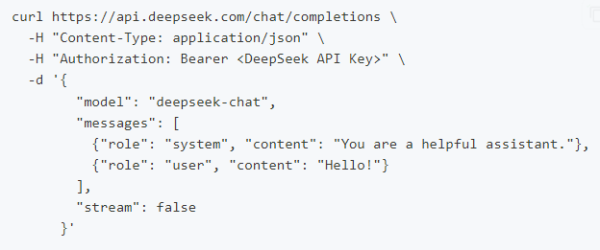
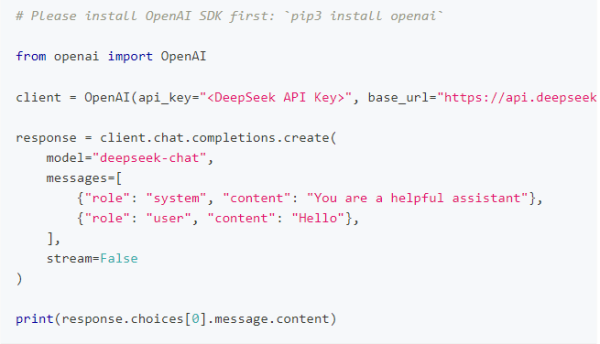
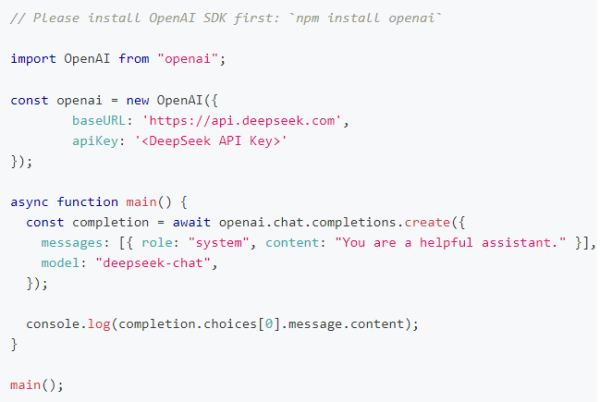
创建 API Key 后,可通过以下示例快速调用 DeepSeek 对话接口(支持流式与非流式输出):
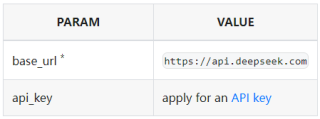
curl 示例:
Python 示例:
Node.js 示例:
R1 如何超越 V3?强化学习的新范式
DeepSeek-R1 与 V3 均基于 V3-Base 基础模型,但 R1 系列引入了全新的后训练范式:**摒弃传统 RLHF(人类反馈强化学习)中的“人类反馈”环节,仅依赖纯强化学习(Pure RL)驱动模型进化**。
在 R1-Zero 的训练中,系统设置了双重奖励机制:一是验证最终答案的正确性,二是评估推理过程的逻辑连贯性。模型会生成多个候选答案,由奖励函数自动评分,从而自主优化解题策略。
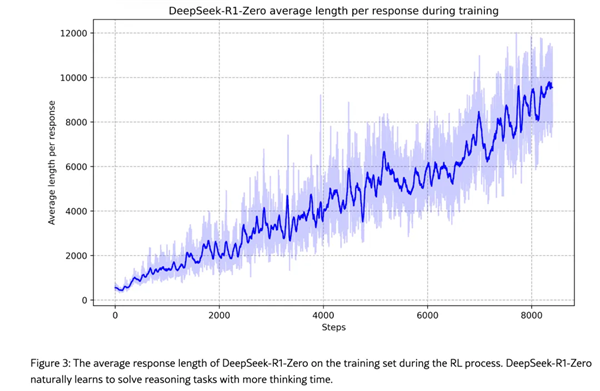
令人惊喜的是,R1-Zero 在训练过程中自发涌现出“反思”行为——它会重新审视初始思路,分配更多计算资源用于复杂问题求解。这种高级认知能力并非人为编程,而是强化学习激励下的自然涌现。
然而,纯 RL 训练初期存在语言流畅性不足、中英混杂等问题。为此,DeepSeek 引入“冷启动”阶段:先用数千条规范的思维链(CoT)数据微调 V3-Base,再注入约 80 万条自生成样本(含 60 万推理相关 + 20 万通用)进行二次微调,最终形成兼具逻辑性与语言质量的 DeepSeek-R1。
值得一提的是,这套 80 万样本数据也被用于微调 Qwen 系列模型,显著提升了其推理能力,验证了该方法的普适价值。DeepSeek 在论文中强调:“这是首个证明 LLM 推理能力可仅通过强化学习激发、无需监督微调(SFT)的开放研究。”
更新日志
v1.0.12 版本
- 修复了登录环节的已知问题



- 厂商:暂无
- 包名:com.deepseek.chat
- 版本:v1.2.1
- MD5值:b021975fd5116410232009409fc0fccf































